Lesson 1.4: How Search Engines Work
Article by: Matt Polsky
For search engines to work, they need to find every page on the internet, add all those pages into a database and run algorithms to determine what types of results to show and the order of results.
More simply put, search engines need to:
- Crawl the web
- Categorize pages in an index
- Rank or order the pages
This process may sound simple, but it's inherently complex. Finding, categorizing and ranking trillions of pages is not a small feat. What's important from an SEO perspective is to have a baseline understanding of how these concepts work.

Crawling
Search engines use programs typically referred to as spiders, crawlers or bots to find all the content on the web. These programs travel from page to page via links, much like a user would, to discover new pages.

Crawlers allow search engines to do two core things:
- Discover new pages which may contain valuable content they want to show users
- Discover when existing pages get updated with new content
Crawlers require an enormous about of resources. There are trillions of pages on the web and a finite amount of server resources to run these programs. Due to this, search engine algorithms try to decide what pages (or websites) deserve to be crawled and how frequently.
Key takeaway: Search engines don't automatically crawl pages over and over again unless they have a good reason to. Good reasons to re-crawl a site or page include things like timeliness, frequency of updates and trust (subjective, but if they determine your site to be spammy, they typically crawl the site less or not at all).
How A Crawler Works
Crawlers fully render pages they land on to obtain all the page's attributes. Rendering a page essentially loads it like your browser does when you search. With the loaded page, a crawler looks for elements that can help with categorization. These elements can include:
- Indexability (does the site owner allow a search engine to index the page)
- Freshness/timeliness
- Content (keywords, quality, structure, layout, type, etc.)
- Perceived authority/expertise (authorship/brand)
- User experience (site speed, layout shifts, ad experience, etc.)
- Internal and external links
- Much, much more
Search engines use this information to determine how to categorize a webpage and where to store it in their index - or if they should store it at all.
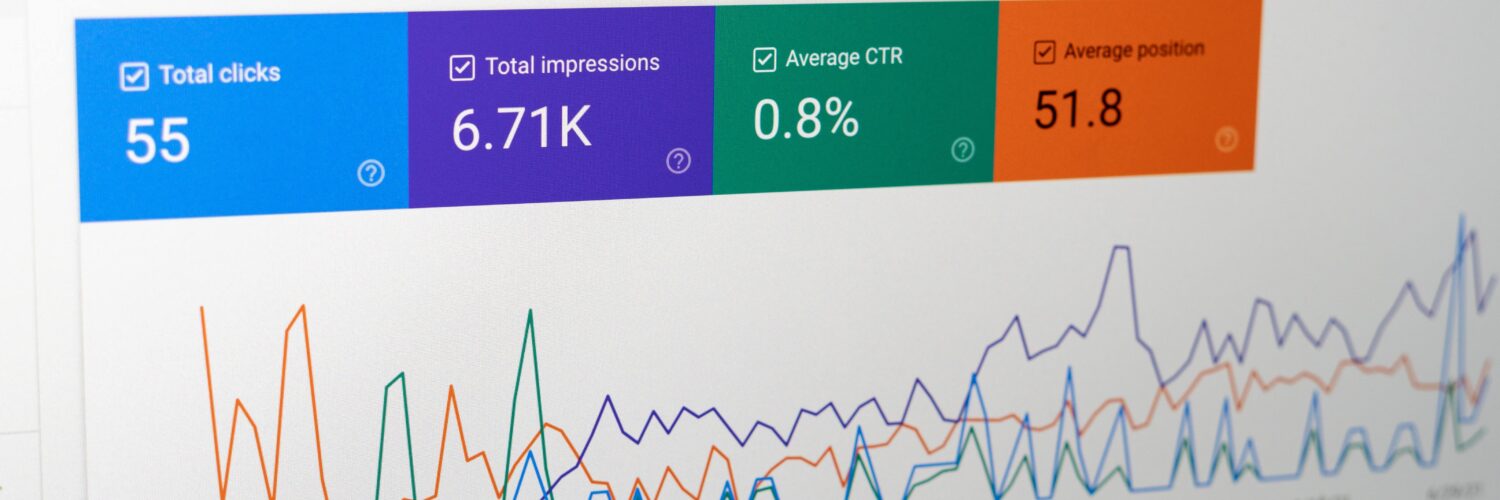
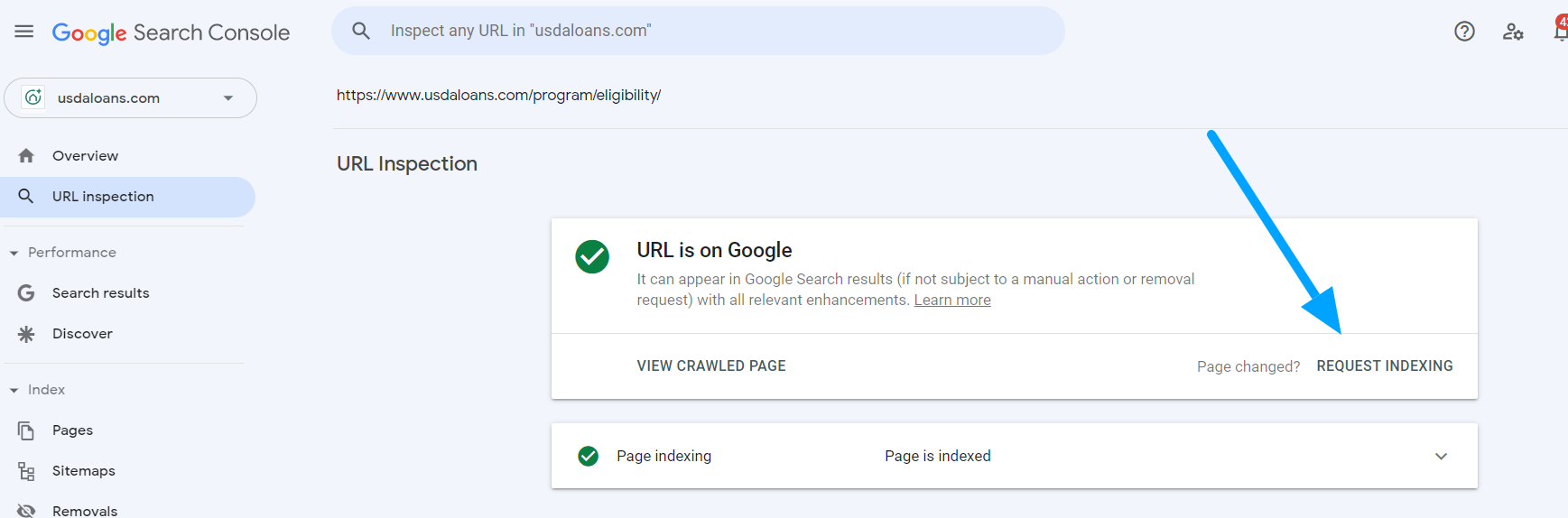
We'll discuss this in our technical SEO lesson, but major search engines also provide site owners with toolsets that can help improve crawling and their search presence. Google's toolset is Google Search Console. Bing's toolset is Bing Webmaster Tools. In both tools, site owners can directly submit URLs into a priority queue or input an XML sitemap to identify the pages to crawl.
Indexing
Once search engines have crawled pages and extracted the attributes, they must pass that information into their index. The index is where search engines store the information from crawling.
The easiest way to visualize the index is by thinking of it as a giant library. All the attributes stored from crawling go in this library in specific places so that search engine algorithms can return them to the user as quickly as possible - a process known as information retrieval.
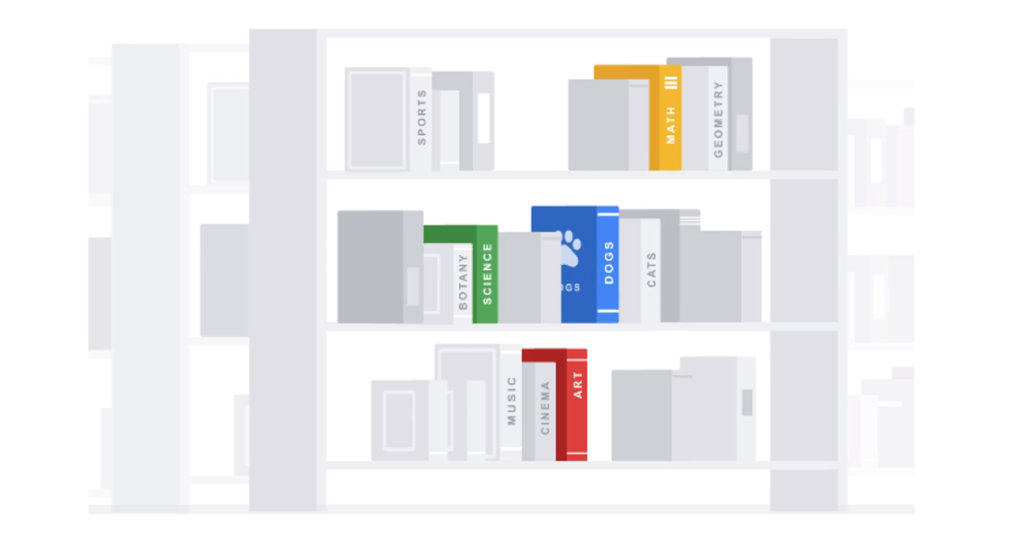
Fun fact: When using Google, or any search engine, you're not searching the web. In fact, you're searching their specific index - or their copy of the web.
Ranking
The last piece is ranking. Upon a search, Google runs a series of algorithms to determine what pieces of content and the order they should appear.
In our next lesson we start looking at search algorithms and how search engines rank a piece of content.