
Lesson 1.5: How Search Algorithms Work
Article by: Matt Polsky
In this lesson, we start diving deeper into search algorithms and how Google ranks a piece of content. We focus on Google because its worldwide search market share is over 91%, and other search engines have similar algorithmic inputs.
What is a Search Algorithm?
An algorithm is a set of mathematical instructions used to reach a specific outcome. In terms of SEO, search engines use algorithms to order results and decide what features a search engine results page (SERP) should include.
It may be easiest to think of an algorithm as a recipe. You include ingredients that most likely determine the quality and adjust the recipe over time to make the perfect dish.
Google has hundreds, if not thousands, of ingredients that go into what pages should rank highest, and this recipe continues to evolve as search behavior changes.

The Original Google Search Algorithm
Other search engines came before Google. Aliweb in 1993, WebCrawler and Lycos 1994 and Yahoo! (search) and AltaVista in 1995. Google didn't come on the scene until 1997. So what made Google different?

Google set itself apart with the quality of results they surfaced. Their algorithm focused on external links (e.g., mysite.com links to yoursite.com) and treated external links as votes. In the first iteration of their algorithm, sites with the most links tended to rank the highest.
This differentiator, known as PageRank, allowed the quality of Google's results to surpass the other search engines of the time.
Links weren't the only factor in Google's original algorithm. As with competing search engines, keywords played an enormous role as well. However, links reduced the ability of SEOs to manipulate search results by simply stuffing keywords in a page or hiding keywords with CSS.
While links provided better search results and were harder to manipulate, they still could be gamed. As we'll see in later lessons, link quality became more important than quantity, and Google began manually penalizing sites with blatant manipulation.
The Need for Continual Updates
SEO as an industry began in 1997. The first known mention of "Search Engine Optimization" came from John Audette of Multimedia Marketing Group (MMG). Later in the year, Danny Sullivan (now a Googler) created Search Engine Watch - a site dedicated to helping website owners rank sites better.
With the birth of a new industry comes both good and bad. On the one hand, you have groups doing great marketing and generally following the rules. On the other hand, you had groups spamming the internet to no end to outrank competitors. The dichotomies became known as "white hat" and "black hat" SEO.

White hat vs. black hat: You may hear the term "black hat" in SEO. Black hat SEO is the practice of going against search engine guidelines to intentionally manipulate SERPs. Examples of black hat SEO include buying links, cloaking (making text the same color as the background to get more keywords on a page), creating hundreds of low-quality sites just to link to a main site and more. Conversely, white hat SEO is when you follow all the "rules." There's an entire forum dedicated to black hat SEO in case you're curious - as with most black hat tactics, the posts there are pretty spammy and not useful (but every so often you may find a good one).
You won't learn much blindly trusting Google and following all their rules, so my hat is gray.
Google isn't a huge fan of anyone manipulating their search results. And now, with an entire industry dedicated to it, they had to make moves and update their algorithms more frequently.
Updating the Algorithm
To keep quality high and mitigate mass manipulation, Google and other search engines have to keep their algorithms up to date. They do this by adding new signals or refining old signals.
Updating the algorithm started as a very manual process involving engineers testing specific inputs and putting those changes in front of a test group to determine whether the result was positive or negative.

The downside is the test group was rarely representative of the entire sample.
Additionally, in this era that lasted generally until around 2015, engineers had to rerun each individual algorithm manually to resort results. With manual refreshes, sites affected by these algorithms wouldn't have the chance to recover until the algorithm ran again. In some cases, that turned out to be more than a year.
Imagine being a business relying on organic traffic and losing it all for 13 or more months. Some businesses in this era closed their doors, or started over with different domains.
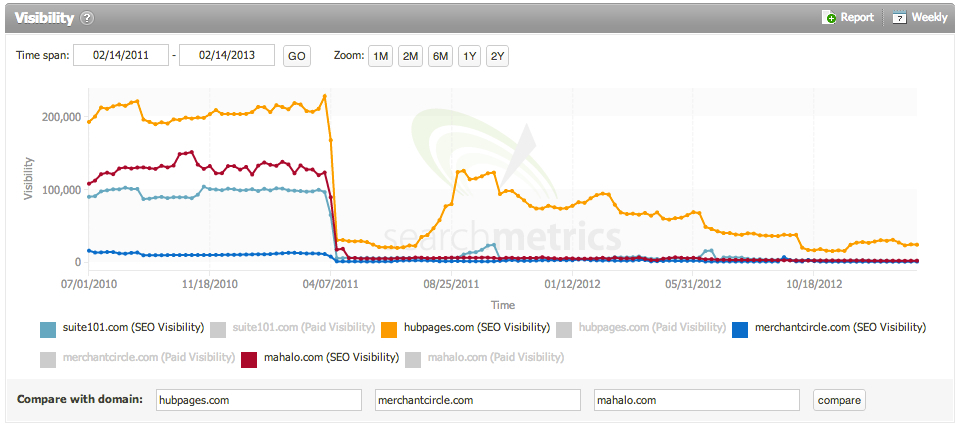
Today, the search quality system hinges more on machine learning (ML) and artificial intelligence (AI) than subjective opinion - though Google employs Quality Raters to review results and the effectiveness of algorithms.
Quality Raters work off criteria given to them by Google to identify ways to make search "more useful." Quality Raters have no direct effect on the algorithm, though they may provide feedback on certain types of results and websites. The quality rater guidelines were once highly coveted, but now Google provides them to everyone. You can view that document here. It's a valuable read.
The Current Algorithm
In reality, Google's algorithm isn't a single script. The algorithm is a collection of algorithms that interpret signals from web pages (i.e., keywords, links, page speed, etc.) to rank the content that best answers a search query. Google claims to release anywhere from 3-5 updates per day every year, though the majority are too small to notice.
However, they typically release a handful of highly prominent updates, which they refer to as "core updates." Highly prominent in this case means site owners would likely see impacts and changes to search results.
Before core, Google released similar-sized updates, but they typically only targeted a narrow type of spam. The smaller targets made it easier for SEOs to determine what factors played into the algorithm and adjust accordingly.
With core, the updates typically cover a breadth of topics and are more challenging to decipher. Google provides advice for sites hit by core updates, which is relatively generic but worth reading.
You can find Google's advice for core updates here.
What Makes Up Google's Algorithm?
Google's algorithm changes constantly. In the mid-2000s, Google claimed there are over 200 factors. However, in the current ecosystem where ML and AI help determine rankings, there's likely thousands of factors and subfactors.
In fact, Google has said a handful of times they don't even know all the factors…

Historically, it's believed there are well over 200 ranking factors - some confirmed, some speculated - but no one outside a select few at Google could say for sure. If you're interested in some of the factors, see this article from Backlinko. They break down some of the known and speculated factors.
Here's What We Do Know
Google wants to show quality pieces of content, so the factors change over time. Many traditional factors still exist but have different weights, or those weights vary.
To complicate things further, factors can change by the page or search intent – meaning the same page may be weighed differently depending on the query.
Traditional Ranking Factors:
- Crawlability (if Google can't crawl the site or see the content, it won't rank)
- Keyword usage
- External links
Newer Ranking Factors:
- User satisfaction (RankBrain)
- Query interpretation (BERT/MUM)
- Freshness
- Mobile-friendliness
- Page speed
- High-quality content (unique/not spun, concise, highly edited and insightful)
- High trust content (from or reviewed by an expert, well-sourced and verified
*Pages involving health, finance, government, people groups, etc. get held to higher standards. Google refers to these queries as "Your Money or Your Life" (YMYL).

BERT and MUM
BERT stands for Bidirectional Encoder Representations from Transformers and is a machine learning, natural language processing (NLP) model that helps search bots understand language as humans do.
Natural language processing is a subfield of linguistics, computer science, and artificial intelligence concerned with the interactions between computers and human language, in particular how to program computers to process and analyze large amounts of natural language data.
MUM is short for Multitask Unified Model and works on transformer technology, similar to BERT. MUM is supposed to be 1000 more powerful than BERT and expands beyond text into image, audio and video content.
BERT and MUM provide a contextual layer on Google's information retrieval (IR) systems that was previously unfathomable. Take the following example:
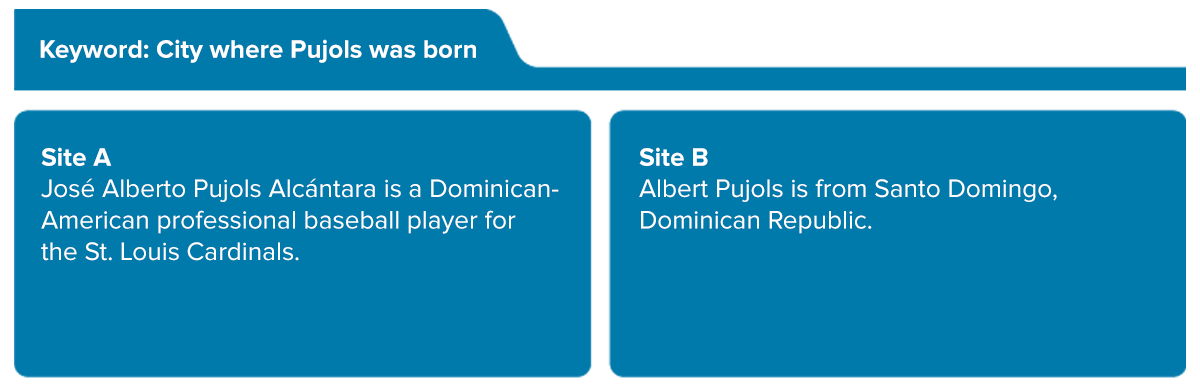
Before BERT/MUM, a query like this would likely show Site A - a Wikipedia or biography of Albert Pujols. Today, it understands more of the context behind the words and would likely show an answer box with the city of his birth, as with Site B.
In our next lesson, we look back at some historical algorithms, how they impacted search as we know it and the tactics we take.